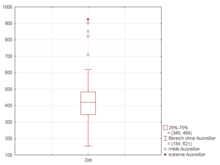
Em estatística descritiva, diagrama de caixa, diagrama de extremos e quartis,boxplot ou box plot é uma ferramenta gráfica para representar a variação de dados observados de uma variável numérica por meio de quartis (ver figura 1, onde o eixo horizontal representa a variável). O box plot tem uma reta (whisker ou fio de bigode) que estende–se verticalmente ou horizontalmente a partir da caixa, indicando a variabilidade fora do quartil superior e do quartil inferior.[1] Os valores atípicos ou outliers (valores discrepantes) podem ser plotados como pontos individuais.[2] O diagrama de caixa não é paramétrico, apresentando a variação em amostras de uma população estatística sem fazer qualquer suposição da distribuição estatística subjacente.[3] Os espaços entre as diferentes partes da caixa indicam o grau de dispersão, a obliquidade nos dados e os outliers.[4] O box plot também permite estimar visualmente vários estimadores como amplitude interquartil, midhinge, range, mid-range, e trimean.[5] Em resumo, o diagrama identifica onde estão localizados 50% dos valores mais prováveis, a mediana e os valores extremos.[6]
Figura 2.Diagrama de caixa dos dados do experimento de Michelson–Morley
Essa ferramenta é usada frequentemente para analisar e comparar a variação de uma variável entre diferentes grupos de dados. Ver como exemplo a figura 2 onde o eixo vertical representa a variável e o eixo horizontal representa o fator de interesse.[6]
Na história da civilização, as imagens sempre foram fundamentais para contar histórias e compartilhar ideias. Na matemática, os primeiros casos de uso de imagem para representar números datam de antes de 300 AC na Grécia Antiga. Mais tarde, os matemáticos desenvolveram o uso de gráficos para ajudar em cálculos mais complexos. Depois de mais de 100 anos desde A Geometria, publicado por René Descartes em 1637, em que o filósofo e matemático francês introduziu o sistema de coordenadas cartesianas, cientistas e matemáticos passaram a usar gráficos para informar e educar com a criação de diferentes tipos de gráficos (gráfico de linha, gráfico de barras e gráfico de pizza) e infográficos. Um dos primeiros registros de uso de gráficos na educação vem do matemático Joseph Priestley (1733 – 1804), que usou gráficos semelhantes ao diagrama de Gantt para ajudar a lecionar história na Warrington Academy. Enquanto que um dos primeiros registros de uso de gráficos na informação vem da enfermeira Florence Nightingale (1820 – 1910), que utilizou gráficos polares para mostrar o número de mortes dentro do exercito britânico.[7]
No decorrer do século XX, a visualização de dados aprimorou–se, sobretudo com a revolução digital que permitiu levar informações gráficas para um público cada vez maior. Em 1969, o matemático John W. Tukey (1915 –2000) popularizou o boxplot.[8] Tukey é pioneiro no processo de análise exploratória de dados, tendo desenvolvido várias técnicas para melhorar a visibilidade e a compreensão dos dados, incluindo o diagrama ramo e folha, o five number summary e o próprio boxplot.[9] Entretanto, embora a criação do boxplot seja atribuída à Tukey, o manual gráfico do pacote estatístico Stata sugere que o diagrama de extremos tenha sido usado pelo menos desde o trabalho The Analysis of Rainfall Probability: A Graphical Method and its Application to European Data, publicado por P. R. Crowe em 1933.[10] Utilizado em várias ciências quantitativas, o modelo pode ser considerado um gráfico estatístico padrão, aparecendo em grande parte dos textos estatísticos introdutórios. Os boxplots tinham vários precursores sob diferentes nomes como o gráfico rangebars e os diagramas de dispersão na geografia e na climatologia.[8]
“
O grande valor de uma imagem é quando ela nos obriga a notar o que nunca esperávamos ver.[7]
Figura 3. Diagrama de extremos com fio de bigodes do mínimo ao máximo
A construção do diagrama inclui os seguintes procedimentos (representando os valores de variável no eixo vertical como nas figuras 2 e 3 por exemplo):
Calcular a mediana e os quartis (o quartil inferior, primeiro quartil , corresponde a 25% das menores medidas e o quartil superior, terceiro quartil , corresponde a 75% das menores medidas). Por exemplo, em , a mediana é elemento , o quartil inferior é o segundo elemento e o quartil superior é o sexto elemento .
Plotar um gráfico, no qual localiza–se a mediana em uma caixa (a base da caixa representa o quartil inferior e o topo da caixa representa o quartil superior lembrando que a variação de variável corresponde a eixo vertical). Portanto, a caixa representa 50% de todos os valores observados, concentrados na tendência central dos valores, eliminando 25% dos menores valores e 25% dos maiores valores (75% - 25% = 50%). A altura da caixa é amplitude interquartil . No exemplo anterior a amplitude interquartil (distância entre os quartis) que determina a altura da caixa é .[6]O mesmo diagrama com fio de bigodes com máximo
Traçar os fios de bigodes ou whisker (os segmentos de reta vertical). Os limites dos fio de bigodes podem representar vários valores alternativos:
O mínimo e o máximo de todos os dados (figura 3);[11] observe que neste caso pela definição não há valores discrepantes. Os fios de bigodes neste caso são: um segmento de reta vertical que liga o topo da caixa ao maior valor observado e outro segmento de reta que liga a base da caixa ao menor valor observado.
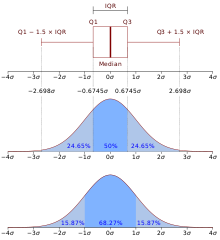
Os limites de fio de bigode é comumente definidos através de limite inferior () e limite superior () de acordo com as seguintes representações matemáticas: e , em que é a amplitude interquartil e é uma constante que pertence aos números reais e pode assumir qualquer valor..[12] Geralmente utiliza–se , porque o valor é capaz de captar mais de 99% dos dados embaixo da curva normal para acima e para abaixo do limites superior Figura 4. Boxplot e função densidade de probabilidade de uma população normal e do limite inferior.[13] Assim, os limites de fio de bigode são o valor mais baixo dentro da amplitude interquartil de 1,5 do menor quartil (ou valor mais baixo dentro de valores maiores de que ) o ponto mais alto dentro da amplitude interquartil de 1,5 do maior quartil (ou valor mais alto dentro de valores menores de que ). Qualquer dado não incluso entre os fio de bigodes deve ser plotado como um outlier com um ponto. Embora pouco usual, um outlier também pode ser representado como um círculo pequeno ou uma estrela (alguns diagramas de caixa também incluem outro caractere para representar a média dos dados).[14] A identificação de outliers é um dos primeiros passos para análise de dados multivariados.[15] Por exemplo, em , o último elemento é um outlier. Geralmente, esses tipos de diagrama são chamados de boxplot de Tukey (figura 4).[14][16] Por exemplo, seja o conjunto de dados , em que a amplitude interquartil é igual a 4. O primeiro quartil ou quartil inferior é . Então, o limite inferior é . Entre e , o maior valor é . Portanto, o fio de bigode inferior é . O terceiro quartil ou quartil superior é . Então, o limite superior é . Entre e , o menor valor é . Portanto, o fio de bigode superior é [12] Não tem valores discrepantes.
O diagrama é uma forma rápida de examinar um ou mais conjuntos de dados graficamente. Embora pareça mais primitivo que o histograma ou a estimativa de densidade kernel, o boxplot apresenta vantagens sobre esses por prover mais dados além da mediana e/ou a média.[17] A escolha do número e da largura das barras pode influenciar muito na aparência do histograma[18] e da estimativa de densidade kernel,[19] o que não acontece com o boxplot. De fato, a largura do diagrama de extremos pode até ser usada como uma medida de informação dos dados, representando em alguma proporção o tamanho do conjunto de dados.[20] Uma comparação (figura 4) entre o gráfico e uma função densidade de probabilidade (histograma teórico) mostra explicitamente a quantidade de informações que essa ferramenta possui.
Pesquisadores têm estudado a temperatura da atmosfera terrestre com a finalidade de evidenciar uma mudança climática que pode alterar as atuais condições de vida no planeta.[21] Seja uma amostra de uma pesquisa realizada com veículos leves emissores de . A amostra compara três (gassol 22, AEHC e GNV), de modo a entender qual deles libera maior quantidade de . Em outras palavras, qual deles mais contribui para o aquecimento global.[22]
O box plot acima indica que o GNV possui 75% da emissão de (abaixo de200 g/km). Isto significa que o GNV é o combustível que menos contribui para o aumento da temperatura da Terra. Esta informação pode ser utilizada para ajudar a combater o aquecimento global de diferentes maneiras como por meio da alteração das fórmulas do 22 e do AEHC.[23]
Em 2016, o Instituto Brasileiro de Geografia e Estatística (IBGE) contabilizou a população dos estados brasileiros.[24][25]
O box plot acima mostra a importância do cuidado com os outliers em análise de dados. A população de São Paulo é maior que a população dos demais estados brasileiros e isso não é um erro. Isto significa que nem sempre o outlier corresponde a um erro de arredondamento ou a um erro de observação.[25]
Figura 6. Quatro boxplots, com e sem entalhes e largura variável
Desde que o matemático John W. Tukey introduziu este tipo de representação visual de dados em 1969, variações do boxplot tradicional têm sido descritas. Duas das mais comuns são os boxplots com largura variável e os boxplots entalhados (figura 6).
Os boxplots com largura variável (variable width box plots) ilustram o tamanho de cada grupo, cujos dados estão sendo plotados tornando a largura da caixa proporcional ao tamanho do grupo. Uma convenção popular é tornar a largura da caixa proporcional à raiz quadrada do tamanho do grupo.[11]
Os boxplots entalhados (notched box plots) aplicam um entalhe ou um estreitamento da caixa em torno da mediana. Os diagramas de caixa entalhados são úteis para oferecer um guia aproximado para a significância da diferença entre medianas. Se o entalhe de duas caixa não se sobrepuserem, isto oferece evidência de uma diferença estatisticamente significante entre as medianas. A largura dos entalhes é proporcional à amplitude interquartil da amostra e inversamente proporcional à raiz quadrada do tamanho da amostra. Entretanto, há incerteza sobre o multiplicador mais apropriados (isto pode variar dependendo da similaridade das variâncias das amostras).[11]
Os boxplots ajustados (variable width notched box plots) são destinados às distribuições distorcidas, baseando—se na estatística medcouple de distorção. Para um valor medcouple de MC, os comprimentos dos fio de bigodes superiores e inferiores são respectivamente definidos por:
Observa–se que para distribuições simétricas, o medcouple será 0. Isto reduz o bloxplot de Tukey como igual comprimento dos fio de bigodes, de amplitude interquartil de 1,5 para ambos os fio de bigodes.[26]
Figura 7. Os digramas podem identificar diferenças entre grupos. Os dados de dois grupos distintos foram mesclados e os gráficos dos três conjuntos mostram como os dados pertencem a grupos distintos
Com o diagrama de extremos, é possível visualizar se existe ou não existe equivalência em conjuntos de dados. A figura 7 mostra que de fato não se trata de um único conjunto, mas de dois grupos A e B distintos. Esta evidência é destacada caso os dados experimentais sejam plotados, em dot plot ou em gráficos de pontos, em conjunto com os diagramas de caixa.[27]
Por exemplo, ao analisar uma variável quantitativa como a renda (salário) de trabalhadores que pode ser expressa (plotada) em dot plot ou box plot, é notado um único gráfico. No entanto, trabalhadores são compostos por gêneros, sendo possível diferenciar entre dois grupos (gêneros) que são homem e mulher. Portanto, ao analisar o diagrama Renda de trabalhadores, se observa dois diagramas de caixa diferentes tratando a mesma variável quantitativa: renda.[28]
Box plot sobre os rendimentos-hora de homens e mulheres. As linhas tracejadas à esquerda representam o percentil 10 e as linhas tracejadas à direita representam o percentil 90. As barras brancas representam a mediana das observações e os x's brancos representam a média
Referências
↑Ross, Sheldon (2004). Introduction to Probability and Statistics ofr Engineers and Scientists 3ª ed. [S.l.]: Elsevier. p. 27. 624 páginas
↑Mann, Prem S. (2010). Introductory Statistics 7ª ed. [S.l.]: Wiley. p. 115 — 117. 625 páginas
↑Navidi, William (2010). «1. Sampling and Descriptive Statistics». Statistics for Engineers and Scientists 3ª ed. [S.l.]: McGraw—Hill Science / Engineering / Math
↑The Open University (2013). «1.1.3 Comparing Data Sets Using Boxplots». Interpreting Data: Boxplots and Tables. [S.l.: s.n.]
↑Rubin, Allen (2013). Statistics for Evidence-Based Practice and Evaluation 3ª ed. [S.l.]: Cengage Learning. p. 67 — 68. 349 páginas
↑ abcDevore, Jay L. (2006). Estatística e Probabilidade para Engenharia e Ciências. [S.l.]: Cengage Learning. p. 35 — 38. 692 páginas
↑Jacobs, Jay; Rudis, Bob (2014). Data–Driven Security: Analysis, Visualization and Dashboards. [S.l.]: Wiley. p. 18. 331 páginas
↑Dietz, Thomas; Kalof, Linda (2009). Introduction to Social Statistics: The Logic of Statistical Reasoning. [S.l.]: Wiley–Blackwell. p. 133. 568 páginas
↑ abcMCGILL, Robert; TUKEY, John W.; LARSEN, Wayne A. Variations of box plots.The American Statistician, v. 32, n. 1, p. 12-16, 1978.
↑Duong, Tarn (4 de maio de 2001). «An introduction to kernel density estimation»(PDF). Weatherburn Lecture Series para o departamento de Matemática e Estatística da University of Western Australia. Consultado em 14 de junho de 2017